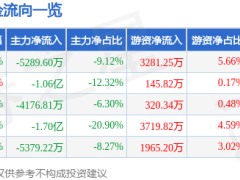
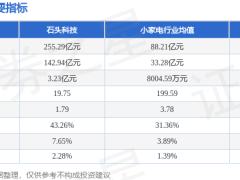
阿里近日宣布推出其首個(gè)原生語(yǔ)言世界模型(LWM)Qwen-AgentWorld,該模型專(zhuān)為AI智能體的研發(fā)與訓(xùn)練設(shè)計(jì),提供35B-A3B與397B-A17B兩種參數(shù)規(guī)模版本。與傳統(tǒng)模型不同,Qwen-AgentWorld的核心目標(biāo)并非降低成本或替代真實(shí)交互環(huán)境,而是通過(guò)內(nèi)部模擬環(huán)境反饋來(lái)增強(qiáng)智能體的決策能力,使其在執(zhí)行動(dòng)作前能夠預(yù)判結(jié)果。
Qwen-AgentWorld的兩大創(chuàng)新點(diǎn)在于:其一,從預(yù)訓(xùn)練階段就將環(huán)境建模納入訓(xùn)練目標(biāo),貫穿CPT→SFT→RL全流程,突破了傳統(tǒng)模型先訓(xùn)練后適配環(huán)境的模式;其二,單一模型可同時(shí)覆蓋文本類(lèi)(MCP、Search、Terminal、SWE)與GUI類(lèi)(Web、OS、Android)共7類(lèi)環(huán)境,實(shí)現(xiàn)跨領(lǐng)域知識(shí)遷移。例如,該模型能模擬手機(jī)系統(tǒng)操作,通過(guò)預(yù)測(cè)點(diǎn)擊刪除圖標(biāo)后的界面變化,驗(yàn)證其環(huán)境理解能力。
為評(píng)估模型性能,阿里同步發(fā)布評(píng)測(cè)基準(zhǔn)AgentWorldBench。該基準(zhǔn)基于5個(gè)前沿模型在9個(gè)真實(shí)環(huán)境交互數(shù)據(jù)集上的表現(xiàn)構(gòu)建,采用開(kāi)放式評(píng)分標(biāo)準(zhǔn),從格式、事實(shí)性、一致性、真實(shí)性和質(zhì)量五個(gè)維度綜合評(píng)估。測(cè)試結(jié)果顯示,397B-A17B版本以58.71分的整體均分超越GPT-5.4(58.25分)、Claude Opus 4.8與Gemini 3.1 Pro,尤其在Terminal和SWE領(lǐng)域表現(xiàn)突出,這得益于其對(duì)代碼執(zhí)行狀態(tài)和工具API行為的精準(zhǔn)模擬。35B-A3B版本通過(guò)三階段訓(xùn)練流水線提升8.66分,性能超越Claude Sonnet 4.6。
進(jìn)一步分析模型思維鏈發(fā)現(xiàn),Qwen-AgentWorld涌現(xiàn)出三種獨(dú)特推理模式:一是自我修正能力,模型通過(guò)“Wait!”信號(hào)觸發(fā)中斷,修正事實(shí)錯(cuò)誤或視角偏差,129個(gè)輪次中平均每輪修正10.4次;二是信息泄漏防護(hù)機(jī)制,在搜索任務(wù)中,模型主動(dòng)屏蔽無(wú)關(guān)查詢(xún)與目標(biāo)答案的關(guān)聯(lián),避免數(shù)據(jù)泄露;三是多步因果推理,例如預(yù)測(cè)“curl -s localhost:3000 | python3 -m json.tool”的輸出時(shí),模型需構(gòu)建6步推理鏈,涵蓋服務(wù)器狀態(tài)、端口監(jiān)聽(tīng)、工具行為等環(huán)節(jié)。
作為統(tǒng)一智能體基礎(chǔ)模型,Qwen-AgentWorld的預(yù)訓(xùn)練能力可直接遷移至多輪智能體任務(wù),覆蓋七個(gè)基準(zhǔn)測(cè)試集,且無(wú)需針對(duì)具體任務(wù)進(jìn)行強(qiáng)化學(xué)習(xí)微調(diào)。這一特性驗(yàn)證了語(yǔ)言世界模型作為構(gòu)建更強(qiáng)智能體基礎(chǔ)的潛力,為突破真實(shí)環(huán)境交互的限制提供了新路徑。目前,阿里已開(kāi)源35B-A3B模型權(quán)重及AgentWorldBench評(píng)估基準(zhǔn),開(kāi)發(fā)者可通過(guò)GitHub、ModelScope和Hugging Face平臺(tái)獲取資源。