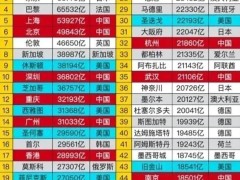
在2025年“兩會”期間,全國人大代表、科大訊飛董事長劉慶峰聚焦人工智能領域,提出加快構建國產算力平臺上的自主可控大模型及產業生態,并針對預防大模型“幻覺數據”危害建言獻策。
劉慶峰指出,在全球人工智能競爭與合作不斷加深的當下,中國人工智能產業實現深度自主可控已成為關鍵議題。他建議,首先要鼓勵基于自主可控國產算力平臺的大模型研發和應用。對投身國產算力芯片研發的企業,以及運用國產芯片訓練大模型的企業,給予專項資金支持,并在國家公共算力分配上予以傾斜,以此加速基于國產算力的大模型算法創新。同時,鼓勵央國企優先采購基于國產算力平臺研發的全棧自主可控大模型,積極推廣此類大模型在行業的垂直應用。
其次,構建數據資源充分共享機制至關重要。依托我國豐富的AI應用場景,大力推動大模型在產業領域的應用,形成數據飛輪效應,使我國率先收獲 AI 產業落地帶來的紅利。
再者,要專項支持基于國產算力平臺的生態體系建設。鼓勵基于自主可控算力底座的大模型開發者生態發展以及開源社區建設,通過專項支持,加快形成國產大模型生態體系和工具鏈,推動我國自主可控人工智能產業生態快速發展。
在預防大模型生成的“幻覺數據”危害互聯網方面,劉慶峰認為,需從技術研發和管理機制層面構建可信的信息環境。
劉慶峰就此提出兩點建議:一是構建安全可信數據標簽體系,提升內容可靠性;二是研發AIGC幻覺治理技術和平臺,定期清理幻覺數據。