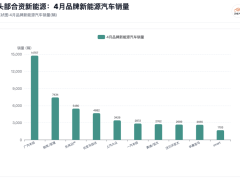
第三方編程評測機構CodeArena最新發布的榜單顯示,阿里通義千問旗艦模型Qwen3.7-Max以1541分的成績躋身全球AI編程能力前列,僅落后于Claude系列模型,在主流大模型廠商中排名第二。此次評測中,該模型超越了GPT-5.5、Gemini-3.5-Flash、GLM-5.1及Kimi-K2.6等知名模型,引發業界關注。
CodeArena的評測機制具有獨特性,其由盲測平臺LMArena開發,采用開發者命題、模型自主生成完整Web應用的方式,最終通過用戶對匿名模型的兩兩對比投票確定排名。這種評測方式更貼近真實開發場景,被視為衡量AI編程實用性的重要指標。阿里技術團隊透露,Qwen3.7-Max專為智能體(Agent)場景設計,在復雜任務處理和長周期運行能力上實現突破。
該模型的核心優勢體現在工程化能力上。據官方披露,Qwen3.7-Max能夠獨立完成傳統需要專業團隊耗時兩周的復雜項目,且在持續運行35小時、調用工具超千次的情況下,仍可完成芯片內核的自我優化編程。這種能力在需要高可靠性的工業級應用中具有顯著價值,特別是在資源受限的邊緣計算場景下表現突出。
開發者社區的反饋印證了模型的實用性提升。多位參與測試的工程師表示,新版本在長程任務自主執行方面表現優異,不僅推理成本較前代降低,輸出速度和代碼質量也有明顯改善。有開發者舉例稱,使用該模型可自動生成包含前后端交互的完整管理系統,代碼結構清晰且具備擴展性,大幅減少了人工調試時間。