阿里近日宣布開源一款名為Qwen-Image-Layered的全新圖像生成模型,該模型首次在行業(yè)內(nèi)實現(xiàn)了類似Photoshop的圖層理解與生成能力,標(biāo)志著視覺大模型技術(shù)邁入新階段。通過創(chuàng)新架構(gòu)設(shè)計,該模型可將圖像分解為獨立圖層,支持近乎零誤差的精準(zhǔn)編輯,有效解決了傳統(tǒng)AI生成圖像在一致性方面的核心難題。

傳統(tǒng)視覺大模型普遍采用"扁平化"處理方式,將圖像視為像素矩陣的簡單疊加,導(dǎo)致物體遮擋、空間關(guān)系等物理特性難以被準(zhǔn)確捕捉。這種技術(shù)局限使得AI生成的圖像在編輯時往往牽一發(fā)而動全身——例如調(diào)整畫面中某個元素的位置時,背景內(nèi)容會同步發(fā)生不可控變化,嚴(yán)重制約了其在專業(yè)設(shè)計領(lǐng)域的應(yīng)用價值。商業(yè)廣告、UI界面設(shè)計等需要高精度控制的場景,至今仍依賴傳統(tǒng)設(shè)計工具完成最終制作。
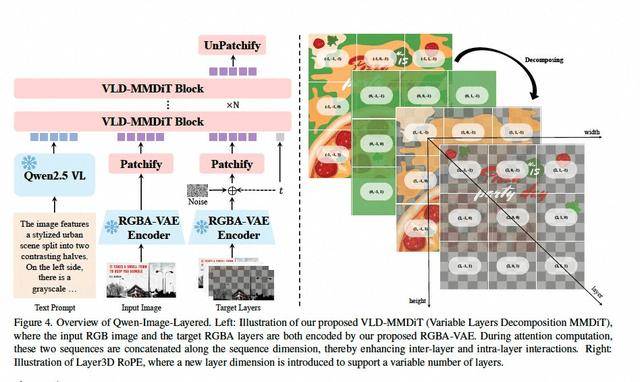
Qwen-Image-Layered通過引入分層處理機(jī)制,構(gòu)建起對三維空間的立體認(rèn)知。研發(fā)團(tuán)隊開發(fā)的RGBA-VAE編碼技術(shù),在傳統(tǒng)RGB色彩模式基礎(chǔ)上新增透明度通道(Alpha),使模型具備圖層分離能力。配合創(chuàng)新的VLD-MMDiT架構(gòu)與3D位置編碼系統(tǒng),模型能夠自動推斷被遮擋區(qū)域的背景紋理,實現(xiàn)從"像素預(yù)測"到"結(jié)構(gòu)重組"的技術(shù)跨越。這種處理方式更接近人類設(shè)計師的思維模式,為圖像編輯提供了前所未有的操作自由度。
為訓(xùn)練這種空間理解能力,研究團(tuán)隊從海量專業(yè)PSD文件中提取圖層邏輯數(shù)據(jù),構(gòu)建起包含復(fù)雜空間關(guān)系的訓(xùn)練樣本庫。這種數(shù)據(jù)驅(qū)動的方式使模型從誕生之初就掌握分層處理的專業(yè)技能,能夠精準(zhǔn)識別不同圖層間的交互關(guān)系。測試數(shù)據(jù)顯示,該模型在物體位移、局部重繪等場景中,可保持97%以上的背景一致性,編輯效率較傳統(tǒng)方法提升4-6倍。
行業(yè)分析師指出,這項突破將重塑數(shù)字內(nèi)容創(chuàng)作流程。設(shè)計師可直接在AI生成的分層圖像上進(jìn)行精細(xì)化調(diào)整,無需手動摳圖或重建背景,使創(chuàng)作過程從"開盲盒"式的隨機(jī)生成轉(zhuǎn)變?yōu)榭煽氐哪K化組裝。影視后期、動畫制作等領(lǐng)域可借此技術(shù)顯著縮短制作周期,降低人力成本。某影視公司技術(shù)負(fù)責(zé)人表示:"該模型讓AI真正成為創(chuàng)作伙伴,而非簡單的素材生成器。"
目前,Qwen-Image-Layered已通過魔搭社區(qū)和HuggingFace平臺開源,允許企業(yè)和開發(fā)者免費商用。這是阿里開源戰(zhàn)略的最新成果,其千問系列模型累計開源數(shù)量已接近400個,全球下載量突破7億次,衍生模型超過18萬個。在企業(yè)級市場,通義大模型以顯著優(yōu)勢占據(jù)國內(nèi)市場份額首位,服務(wù)客戶數(shù)量突破100萬家,形成覆蓋多行業(yè)的AI應(yīng)用生態(tài)。